The remarkable growth of Statsig over the past year, with a staggering 20X increase in event volume, reflects the platform’s crucial role in enabling teams to enhance their product development speed.
Notably, high-profile customers such as OpenAI, Atlassian, Flipkart, and Figma have chosen Statsig’s platform for its advanced features in experimentation and analytics.The fact that Statsig is now processing over a trillion events daily showcases a substantial achievement for the organization.
Particularly as a startup, attaining such a significant volume underscores their technical capabilities and the value they provide to their customers.Nonetheless, this exponential growth also brings forth substantial challenges for Statsig to navigate and overcome effectively. As the demand and expectations placed on the platform continue to surge, the team at Statsig must address issues related to scalability, performance optimization, and maintaining the quality of service for their expanding user base. By implementing robust strategies and solutions to tackle these hurdles, Statsig can ensure sustained success and continued satisfaction among their clientele.
Statsig’s Streaming Architecture
Remarkable Growth and Its Implications
In the past year, Statsig has experienced an astonishing 20-fold surge in the volume of events it processes. This dramatic growth can be attributed to its collaboration with high-profile clients such as OpenAI, Atlassian, Flipkart, and Figma, who depend on Statsig’s advanced capabilities for experimentation and analytics to enhance their products.
Handling over a trillion events every day is a testament to Statsig’s capability and scalability, especially considering its status as a growing startup.
Challenges Arising from Rapid Expansion
However, such rapid expansion introduces significant challenges. Statsig must not only scale its infrastructure to accommodate the vast influx of data but also ensure its systems maintain reliability and high uptime. Furthermore, it is crucial to manage costs efficiently to uphold competitiveness in the marketplace.
Overview of Statsig’s Streaming Architecture
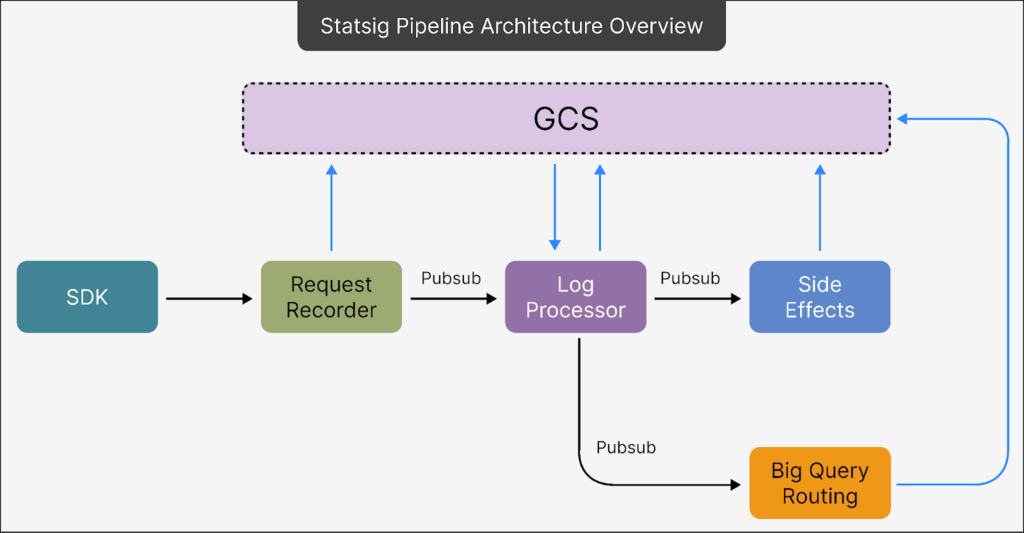
Statsig’s sophisticated streaming architecture is designed to effectively manage the high volume of events. It comprises three essential components:
- Request Recorder: The primary function of this component is to ensure every piece of data is captured and stored securely. It prioritizes data integrity and completeness, ensuring no data is lost during the recording process.
- Log Processing: In this phase, raw data gathered by the request recorder undergoes refinement. Specific rules and logical operations are applied to ensure the data is accurate and ready for subsequent use.
- Routing: Acting as a smart traffic management system, this component directs processed data to its appropriate destination, allowing the pipeline to cater to varied customer requirements without necessitating separate systems for each use case.
Detailed Examination of Architectural Components
To gain a deeper understanding of Statsig’s pipeline, let’s delve into each component:
- Data Ingestion Layer Serving as the foundational step, this layer is critical for receiving, authenticating, organizing, and securely storing data to prevent any loss, even under challenging conditions. The request recorder plays a pivotal role here by managing the initial handling of incoming data. Additional functionalities include load balancing, authentication, rebatching, and ensuring data persistence.
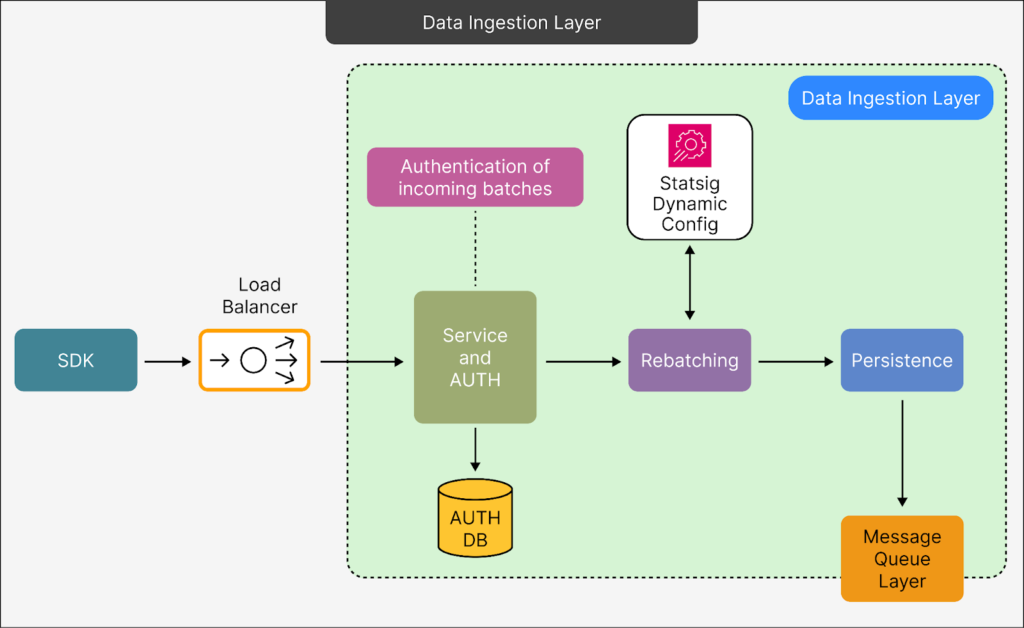
- From Client SDKs to Load Balancer: Initially, data from client SDKs passes through a load balancer, which evenly distributes requests across servers. This distribution helps maintain system stability and optimal performance by preventing server overloads.
- Service Endpoint & Authorization: Upon reaching the server, data is authenticated to confirm that only valid and authorized data batches proceed for processing. This step is crucial for maintaining data integrity and security. The data is then placed in an internal queue, ensuring that even if processing is delayed, no data is lost.
- Rebatching for Efficiency: At this stage, smaller batches of data are combined into larger ones, a process known as rebatching. Handling fewer, larger batches improves both performance and cost-efficiency. The optimized data is then written to Google Cloud Storage (GCS), a more economical choice compared to streaming smaller batches through high-cost pipelines.
- Persistence for Reliability: Post-rebatching, data is stored in a persistence layer equipped with multiple fallback options. These backups are crucial for storing data in cases where the primary system faces issues, ensuring system continuity during outages.
- Message Queue Layer This layer is integral to managing the flow of data between various components, designed to efficiently handle large volumes while keeping operational costs low.

- The Pub/Sub Topic: As a serverless messaging system, Pub/Sub facilitates communication across different parts of the pipeline without the need for server maintenance, thereby reducing overhead. It functions by storing metadata that acts as pointers to the actual data housed in GCS.
- GCS Bucket: To minimize expenses, most data is stored in GCS using compressed batches. Pub/Sub retains only the essential metadata required for data retrieval from GCS. The data is compressed using Zstandard (ZSTD), which offers superior compression rates and lower CPU usage compared to alternatives like zlib, ensuring efficient storage and quick processing.
- Business Logic Layer This layer is where intensive data processing occurs, ensuring data is prepared accurately for downstream applications. It handles complex logic, customization, and formatting.
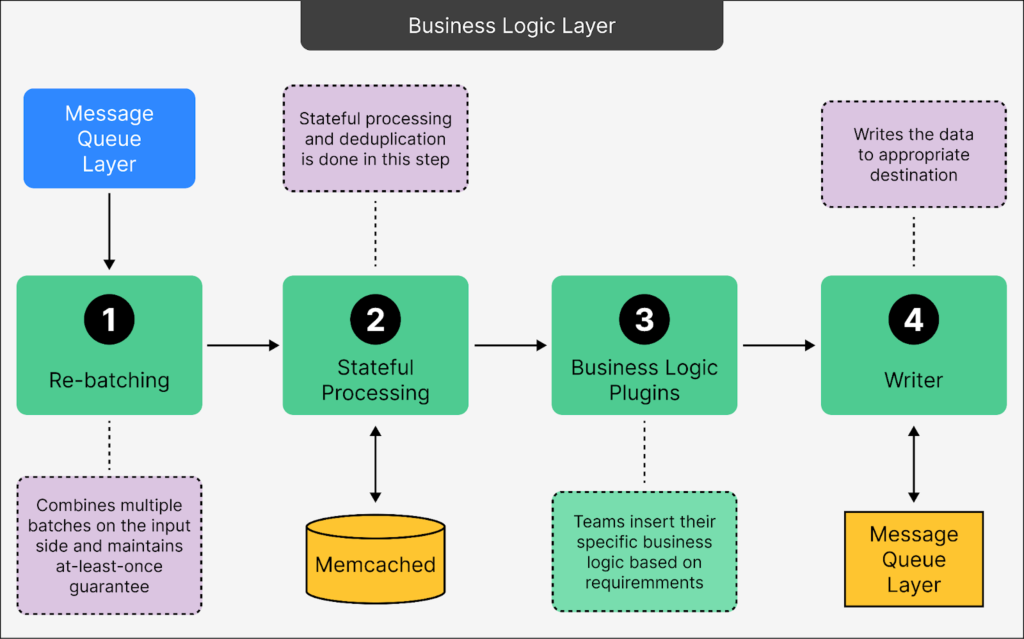
- Rebatching: This process involves merging smaller data sets into larger ones for more efficient processing. The system guarantees that no data is lost, even if errors occur, by retrying processing until successful completion.
- Stateful Processing to Remove Redundancy: This step focuses on deduplication, filtering out redundant or repeated data entries. Caching solutions like Memcached facilitate quick access to previously processed data, enabling efficient identification and removal of duplicates.
- Business Logic Plugins: This feature allows different teams within Statsig to integrate custom logic tailored to specific needs. It supports a wide variety of use cases without necessitating separate pipelines for each, thereby enhancing the system’s scalability and adaptability.
- Writer: Once data has been refined and customized, the Writer finalizes it by directing it to the appropriate destination, be it databases, data warehouses, or analytics tools.
- Routing and Integration Layer This layer manages the direction of processed data to its final destination, tailored to meet specific customer needs.
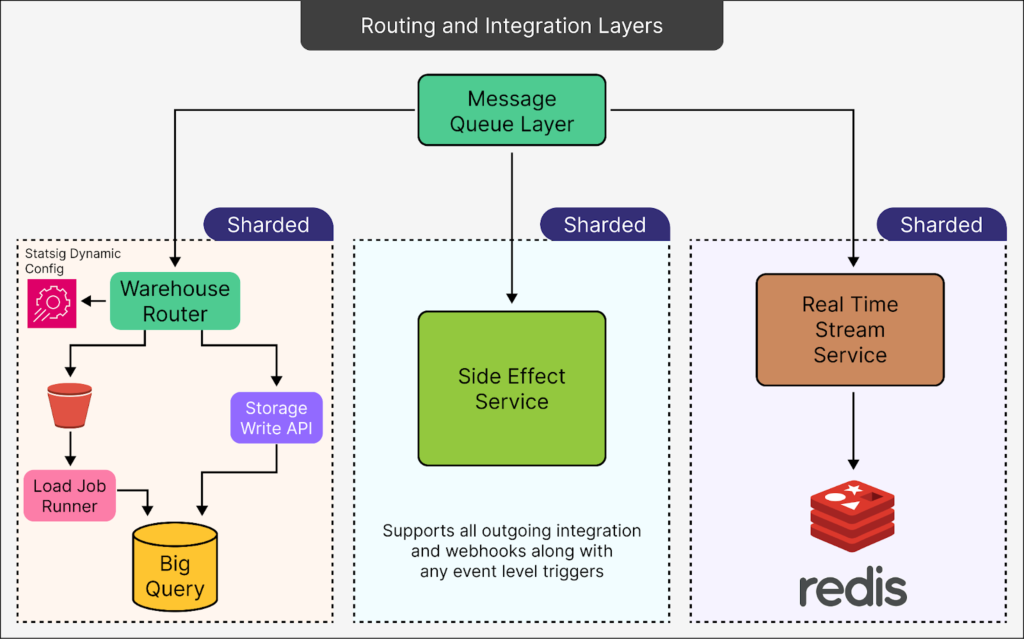
- Warehouse Router: This system determines data destinations based on factors such as customer preferences, event types, and priorities. Batch processing is employed for non-urgent data, while real-time streaming is used for time-sensitive data, ensuring efficient resource utilization without compromising performance.
- Side Effects Service: This service handles external integrations triggered by specific pipeline events, offering extensive customization options for client workflows.
- Real-Time Event Stream: Designed for scenarios requiring immediate data access, it provides instantaneous updates for applications like real-time dashboards. Redis is used to facilitate rapid data retrieval, minimizing delays for users accessing the data.
- Shadow Pipeline: A crucial testing feature, the Shadow Pipeline ensures that system updates do not interfere with the ability to process events effectively. It simulates real traffic conditions, allowing for comprehensive evaluation and testing.
Strategies for Cost Optimization
To address the challenge of processing massive volumes of data daily, Statsig employs several cost-saving strategies, blending technical solutions with smart infrastructure choices:
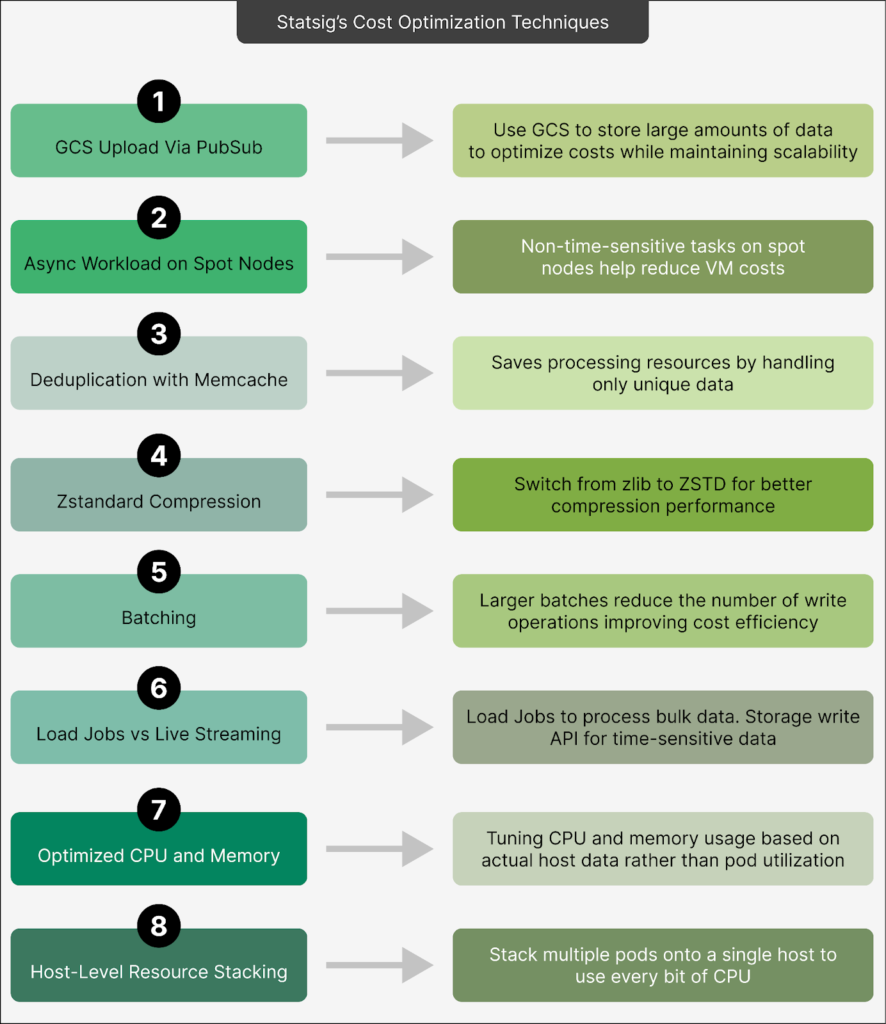
- GCS Upload via Pub/Sub: By storing bulk data in GCS and using Pub/Sub for metadata only, Statsig significantly cuts down on costs while maintaining scalability.
- Async Workloads on Spot Nodes: Non-urgent tasks are executed on cost-effective spot nodes, reducing virtual machine expenses.
- Deduplication with Memcache: Early identification and removal of duplicate events help conserve processing resources.
- Zstandard Compression: This efficient compression method reduces storage requirements and processing power, offering better rates than zlib.
- Batching Efficiency via CPU Optimization: Adjusting CPU allocation allows for larger data batches, reducing storage operations and improving cost efficiency.
- Optimized CPU and Memory Utilization: Fine-tuning resource usage based on actual host utilization prevents underutilization and maximizes efficiency.
- Aggressive Host-Level Resource Stacking: By stacking multiple pods on a single host, Statsig optimizes resource use, reducing the need for additional machines.
Conclusion
Statsig’s journey to managing over a trillion events daily showcases how strategic engineering and innovative design can achieve massive scalability and efficiency. By developing a robust data pipeline with essential components and implementing effective cost management strategies, Statsig supports rapid growth while ensuring reliability and performance. These efforts enable Statsig to offer competitive pricing and ensure resilience, setting it apart as a leader in the field.